Real Results from Virtual Worlds
Imagine you’re a developer on your first day at a new job. You’re handed a state-of-the-art sensor designed to capture data for an autonomous vehicle. The excitement quickly turns to anxiety as you realize the monumental task ahead. Testing this sensor in the chaotic real world feels daunting, if not terrifying. The thought of navigating through unpredictable variables, ensuring safety, and capturing accurate data amidst endless potential obstacles is overwhelming. Now, take a deep breath.
What if, instead of deploying this sensor into the chaotic real world for testing, you plug it into a computer and load up a virtual environment? Imagine a detailed simulation that mirrors real-world conditions—complete with fluctuating weather, diverse terrain, and various objects and obstacles. This is the transformative power of synthetic data—where the line between virtual and reality blurs, offering an unprecedented playground for innovation and precision in sensor development.
Over the years, I’ve watched technology evolve from the realm of sci-fi into practical, life-enhancing tools. One of the most thrilling developments? Synthetic data. This concept is redefining how we develop, test, and deploy sensor systems across various domains.
The Power of Synthetic Data
Synthetic data is like creating a digital twin of the real world. Instead of collecting data from real-life events, we generate it using simulations, generative models, and other advanced techniques. For machine learning applications, especially those involving physical sensors, it offers a versatile and practical solution to many challenges. It enables us to test and train models in a controlled environment, speeding up development and enhancing the reliability of our solutions.
Training Before Sensor Development
Synthetic data allows you to train ML models even before the physical sensors are ready. By simulating the sensor’s data output, developers can start refining ML models early, identifying potential issues and saving significant time in the development cycle. This preemptive approach not only accelerates development but also enables iterative improvements. As the models encounter the generated data reflecting various scenarios, developers can fine-tune algorithms, making adjustments based on insights gained from the virtual environment. This early training helps in creating a more robust and well-calibrated model by the time the actual sensor hardware is available.
Photorealistic and High-Fidelity Data
With advancements in computer graphics and simulation technologies, synthetic data can closely mimic real-world conditions. This is crucial for autonomous vehicles, where high-fidelity data is needed to train models under diverse driving scenarios and weather conditions, ensuring robust real-world performance. For instance, it can replicate scenarios like heavy rain, snow, fog, or complex urban environments with high traffic density. These photorealistic simulations enable ML models to learn from a wide array of conditions that might be difficult or dangerous to encounter during real-world testing. By exposing models to this variety, developers ensure that the algorithms can generalize well, improving the vehicle’s ability to handle real-world unpredictability.
Enhanced Testing and Validation
Synthetic data enables exhaustive testing of ML algorithms under controlled conditions. This is particularly beneficial for sensor applications, where real-world testing can be costly, time-consuming, or even dangerous. It allows developers to rigorously test their models, ensuring reliability before field deployment. This controlled testing environment allows for the creation of edge cases and rare scenarios that might not occur frequently in real life but are critical for safety and performance. Additionally, synthetic data provides a consistent and repeatable testing framework, ensuring that all iterations of the model are subjected to the same conditions, which helps in identifying and addressing flaws systematically.
Synthetic Data in Sensor Applications
Sensors are everywhere in modern technology, embedded in everything from home thermostats to the complex LiDAR systems guiding autonomous vehicles. These sensors collect vast amounts of data, which machine learning algorithms use to make sense of the world. However, gathering real-world data for training these algorithms can be challenging and time-consuming. This is where synthetic data comes in. By generating realistic data through simulations and generative models, we can provide machine learning algorithms with a versatile and practical training ground, speeding up development and improving accuracy.
Accelerating Development Cycles
Traditionally, developing sensor-based ML systems follows a sequential path: first, the sensor is built, then data is collected, and finally, the model is trained. Synthetic data changes the game by enabling parallel development of sensors and ML models. While the sensor hardware is still in the design and testing phases, ML models can already be trained and optimized using simulated data. This concurrent approach slashes the time to market, allowing for faster innovation.
Handling Edge Cases
A major challenge in ML training is acquiring enough data for rare or extreme conditions, known as edge cases. These might include uncommon weather events for climate sensors or unusual driving scenarios for automotive sensors. Synthetic data can be tailored to include a wide range of edge cases, ensuring that ML models are robust and well-prepared to handle these situations when they arise in the real world.
Cost and Resource Efficiency
Collecting real-world data is often costly and resource-intensive. For instance, training an ML model for autonomous vehicles requires extensive driving in varied conditions, which demands significant time, labor, and equipment. Synthetic data provides a cost-effective alternative, offering an almost unlimited supply of training data without the need for physical data collection efforts. This not only saves money but also streamlines the development process.
The Broader Impact of Synthetic Data
As industries increasingly adopt machine learning, especially in areas where sensor technology is critical, synthetic data is proving to be a versatile and transformative tool. This technology enables the creation of realistic, high-quality datasets that can be used to train and validate ML models, providing significant advantages across various fields. Here’s how synthetic data is making an impact in some key areas:
Robotics
In robotics, sensors are essential for navigation, object detection, and interaction with the environment. Synthetic data can train ML models to handle complex tasks such as obstacle avoidance, path planning, and manipulation in dynamic environments. For instance, robots operating in warehouses can be trained using synthetic data to recognize various objects, optimize their routes, and ensure safety protocols, improving efficiency and safety without the need for extensive real-world testing. This approach not only enhances the robot’s performance but also ensures it can operate safely around humans and other machinery, reducing the risk of accidents.
Healthcare
In medical diagnostics, sensors are used to monitor patient health parameters continuously. Synthetic data can be used to train ML models to recognize patterns and anomalies in medical data, potentially improving early diagnosis and personalized treatment plans. For instance, synthetic electrocardiogram (ECG) data can potentially be generated to train models for detecting cardiac anomalies without the need for extensive clinical trials.
Manufacturing and Industry 4.0
In smart manufacturing, sensors are used to monitor machinery and production processes. ML models trained on synthetic data can predict equipment failures, optimize maintenance schedules, and enhance overall operational efficiency. Synthetic data can simulate various machine states and failure modes, providing comprehensive training datasets for ML algorithms.
Environmental Monitoring
Sensors deployed for environmental monitoring collect data on air quality, water quality, and other ecological parameters. ML models trained with synthetic data can analyze these datasets to detect pollution patterns, predict environmental changes, and assist in conservation efforts. Synthetic data can simulate different environmental conditions, helping to build more resilient and adaptive ML models.
Overcoming Challenges and Ensuring Realism
Synthetic data opens up incredible possibilities, but it’s not without its hurdles. To harness its full potential, we need to ensure the data’s realism and accuracy. Let’s dive into some key strategies for tackling these challenges:
Realism and Fidelity
The magic of synthetic data lies in its ability to mirror the real world. For ML models to be effective, it must replicate the statistical properties and visual nuances of real data. Techniques like domain randomization, which involves randomizing elements within the synthetic environment, help models become more adaptable to real-world variations. Additionally, advances in generative adversarial networks (GANs) allow us to create data so realistic, it’s almost indistinguishable from the real thing.
Validation Against Real Data
While synthetic data is powerful, grounding it with real-world data enhances its reliability. A hybrid approach, blending synthetic and real data, can significantly boost the robustness of ML models. This means initially training models on synthetic data and then fine-tuning them with real-world data to ensure they perform accurately in real-life situations. This combination ensures our models are both innovative and practical.
Ethical and Bias Considerations
Creating synthetic data responsibly is crucial. We must be vigilant about potential biases in the generated data. Ensuring diversity in synthetic datasets helps prevent ML models from adopting and amplifying existing biases. This is especially critical in sensitive areas like healthcare and law enforcement, where biased models can lead to serious ethical issues and consequences.
The Future of Synthetic Data in ML
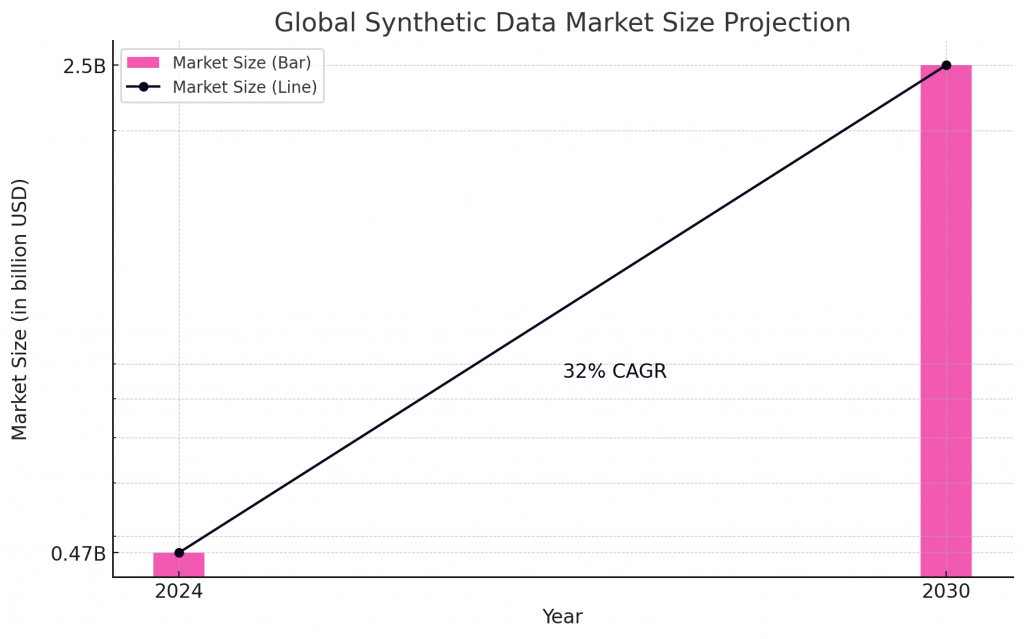
We’re standing at the cusp of an exciting frontier, with advancements in data generation techniques constantly pushing the boundaries. The Global Synthetic Data market size is predicted to reach $2.5 billion by 2030, growing at a CAGR of 32% during the forecast period 2024-2030 according to the latest market research report published by IndustryARC.
The allure of synthetic data is undeniable, and its increasing adoption across industries is set to change the game.
In the fast-paced realm of machine learning, the demand for top-notch synthetic data is set to skyrocket, sparking a wave of innovation. Companies and researchers will be racing to develop ever more sophisticated tools and methods for generating and validating data. Think of it as the arms race of the data world, but with fewer missiles and more algorithms.
For ML practitioners working with sensors, synthetic data is proving to be a real game-changer. Integrating synthetic data into the development pipeline is quickly becoming the gold standard. Imagine being able to rigorously train and test ML models before a single physical sensor hits the field. This not only speeds up development but also dramatically boosts the quality and reliability of the final product. It’s like having a crystal ball that predicts and solves problems before they even happen.
Conclusion
Looking ahead, the symbiotic relationship between synthetic data and machine learning will unlock unparalleled possibilities, transforming hurdles into springboards. As we continue to stretch the limits of innovation, it will play a starring role in driving progress and ensuring top-notch outcomes across a myriad of fields.